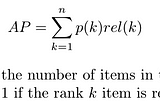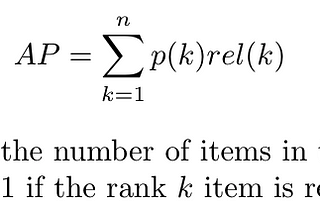PinnedBenjamin WanginTowards Data ScienceMonte Carlo Tree Search: An IntroductionMCTS is the cornerstone of AlphaGo and many AI applications. We aim to build some intuitions and along the way get our hands dirty.Jan 10, 20212Jan 10, 20212
PinnedBenjamin WanginTowards Data ScienceRanking Evaluation Metrics for Recommender SystemsVarious evaluation metrics are used for evaluating the effectiveness of a recommender. We will focus mostly on ranking related metrics…Jan 18, 2021Jan 18, 2021
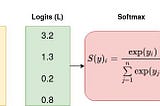
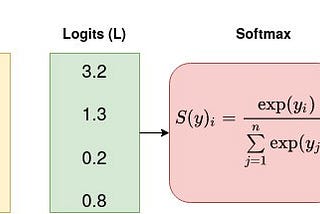
PinnedBenjamin WanginThe StartupCross Entropy Loss in PyTorchA small tutorial for newbie using cross entropy loss in PyTorch.Jan 13, 2021Jan 13, 2021
PinnedBenjamin WanginTowards Data ScienceMatrix Factorization in Recommender Systemsgentle intro into Matrix Factorization (MF) techniques in Recommender Systems (RS). Including FunkSVD , SVD++, and NMF.Jan 5, 20211Jan 5, 20211
PinnedBenjamin WanginTowards Data ScienceBack to Basics: Nearest NeighboursDeep learning is over-hyped, it’s time to go back to the basics.Jan 4, 2021Jan 4, 2021
Benjamin WanginTowards Data ScienceML Pipelines with Grid Search in Scikit-LearnML Pipeline is an important feature provided by Scikit-Learn and Spark MLlib. It unifies data preprocessing, feature engineering and ML…Jan 26, 20212Jan 26, 20212
Benjamin WangLocality Sensitive HashingLSH is a technique used to find similar documents in a large corpus. Here we use “documents” in a broad sense to represent any data that…Jan 25, 2021Jan 25, 2021
Benjamin WangBloom filterBloom filter is a probabilistic data structure designed to tell you if a member is in a set in a highly memory and time efficient manner…Jan 25, 2021Jan 25, 2021